How to train a centralized AI/ML model on a decentralized data securely?

 Cite this article
Cite this article
An exciting new era in computing is upon us, with AI and ML playing an ever-increasing role in our daily lives and professional aspirations.
There is an increasing need to train AI/ML models on data distributed over a decentralized network as these technologies mature and advance.
It might be challenging to obtain and use training data since it is often stored in a single place. Even more concerning is the fact that security breaches to centralized databases might compromise the personal information of both people and businesses.
But decentralized information is spread out throughout a group of machines, so it's easier to access and secure to store.
However, it might be difficult to train an AI/ML model using decentralized data because of its inherent diversity and lack of organization.
In this article, we will discuss the security implications of training a centralized AI/ML model using distributed data.
We'll go through the advantages of training on distributed data, the difficulties that might arise, and the methods that have been developed to deal with them.
Some advantages of training using distributed data
Training an AI or ML model on decentralized data comes with several important advantages.
As it is not kept in one central place, decentralized data is simpler to obtain than centralized data. When training data is dispersed over many sites, this may be very useful.
Second, there are less opportunities for security breaches with decentralized data, making it safer than centralized data.
Third, decentralized data is more reliable than centralized data because it does not face the same risks of data loss.
Fourth, since it is simple to replicate over a network of computers, decentralized data is more scalable than centralized data.
Fifth, decentralized data is more adaptable to new AI/ML models than centralized data.
The challenges of training with decentralized data
While there are numerous upsides to training on distributed data, there are also certain drawbacks that must be considered.
To begin with, it might be challenging to train an AI/ML model using decentralized data because of its inherent heterogeneity and lack of structure.
Second, it might be challenging to guarantee that all data is utilized for training when data is distributed in a decentralized manner.
Third, it might be hard to evaluate various models due to the absence of standardization in decentralized data.
A fourth issue is that it might be challenging to update and enhance the model due to the distributed nature of the data.
Methods for training with distributed data
There are a variety of methods for training an AI or ML model using distributed data.
The first method involves using a federated learning algorithm, a subset of machine learning that allows models to be trained using data that is geographically dispersed among a group of computers.
Another option is to use a distributed learning method, a kind of machine learning that enables models to be trained using data that is physically split among several computers.
As a third option, you may use a transfer learning method, a subset of ML that permits training models using information that is peripheral to the current job at hand.
The fourth strategy involves making use of a reinforcement learning algorithm, a subfield of machine learning that enables models to be trained on data with the help of a reinforcement agent.
Fifth, you may train your models using both labelled and unlabelled data with the help of a semi-supervised learning algorithm.
Data is progressively distributed across many devices and servers, reflecting a more decentralised global environment. Despite this, centralised AI and ML models remain preeminent due to their greater capacity for rapid data training.
So, is it possible to train a centralized AI/ML model on decentralized data securely?
In short, yes, but with some additional work, you can train a centralised AI/ML model on safely dispersed data.
The first step is to accumulate data from all the distributed devices. You may gather this information by hand, or you can automate the process using software.
The next step is to prepare the data for analysis. Making ensuring the data is spotless and prepared for training is an essential first step.
Once the data is gathered, the centralised AI/ML model can be trained on it. TensorFlow or PyTorch are two possible tools for this task.
It might be difficult to train a centralised AI/ML model on distributed data, but it is doable. With proper data collection and cleaning, a high-quality AI/ML model may be trained for use in decentralised data prediction.
Training ML models in isolated containers is now possible in the cloud or on-premises using Fortanix Runtime Encryption (RTE) technology. The model's sensitive data and/or application code are kept entirely inside the confines of the company. To remotely authenticate the authenticity of an enclave running an ML model, our product, Confidential AI, allows secure connection (SSL) communications that end within a secure enclave.
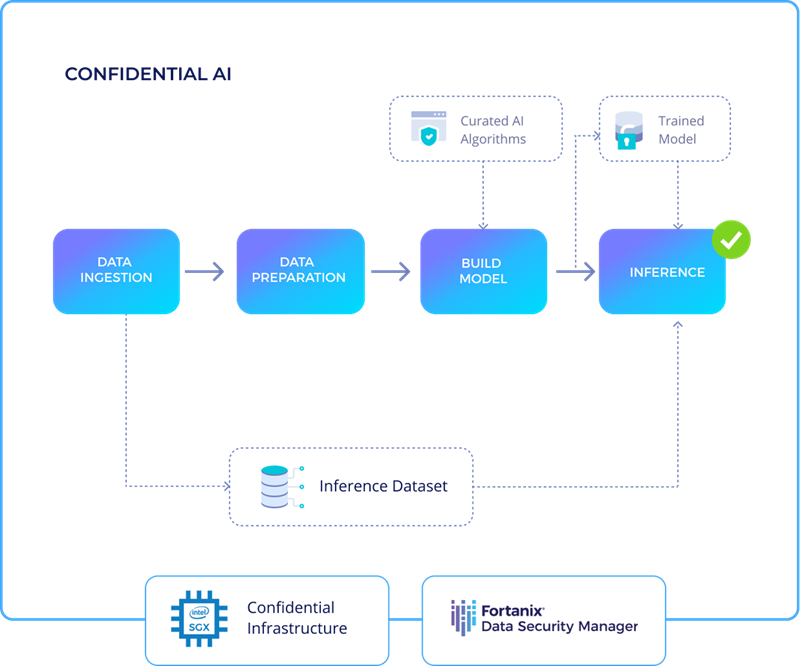
Just to recap, in this article, we looked at a way to safely train an aggregative AI/ML model using data that is stored in many locations.
The advantages, difficulties, and methods for overcoming such difficulties in training on decentralized data have all been examined & discussed a next-gen approach to solve this challenge.





