Protecting Kafka with Fortanix DSM


Introduction to Apache Kafka
There are very few platforms that have achieved such a high adoption rate in Fortune 100 companies as Apache Kafka. It has become the de facto standard for event streaming of data. In contrary to regular databases, Kafka focuses on events and not on things, like it is done in common relational databases.
The general concept is surprisingly simple; Kafka retrieves data (so-called Events) from an entity (so-called Producer) writes it into an immutable log (so-called Topic), may modify/aggregate the data and forwards this information to another entity (so called Consumer).
The strengths of Kafka are its capability to support real-time applications and its enormous flexibility. This flexibility is mainly achieved by Kafka’s ability to connect to almost every 3rd party application. This is done with Kafka connectors.
These connectors exist for almost every data source and, due to its open-source nature, anybody can even build its own connector. An exemplary architecture with integrations into numerous 3rd party applications as shown in Figure 1 can be set up with ease.
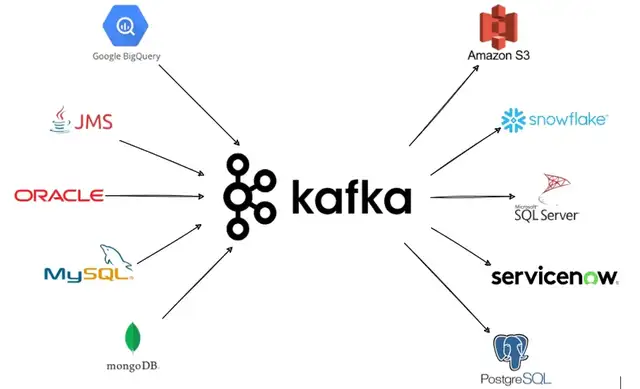
Figure 1: Sample Kafka Architecture
The data sources on the left of the diagram are typically connected with Source Connectors. For the target sources on the right of the diagram so-called Sink Connectors are used.
Data Protection
Though providing huge flexibility and feature-richness, Kafka does not feature any means to protect its data out-of-the-box. To achieve this, typically applications encrypt their own data, like it is e.g. provided by many database vendors through TDE.
The lack of inbuilt data encryption is a serious issue, as ransomware attacks are rising and regulations like California Customer Protection Act (CCPA), General Data Protection Rules (GDPR) and Network and Information Security (NIS2) demand proper protection of your data.
Encryption of the data incurs the usage of digital keys. And of course, you cannot leave the keys right under your door mat. These need proper protection as well. Ideally, they are stored within a hardware security module (HSM). This is a tamper-evident crypto keystore, which should be compliant to the NIST standard FIPS 140-2 Level 3.
Tokenization
Protecting sensitive data is paramount. But when protecting data, people first think of encryption, e.g. with AES. Though encryption fulfills the requirement for confidentiality, it brings some difficulties into the game.
Encryption operations change the format of the data. The character set is changed, as encrypted data is an arbitrary sequence of bytes and its length changes. That makes encryption unusable for many existing applications, as these may rely on a strict data model. Applying encryption to legacy applications can lead to application failure.
So, what is the solution? Thankfully, there is Tokenization. Tokenization is a format preserving encryption (FPE). This means the character set and the data length are preserved, so the tokenized data are still matching existing data models.
Still, the confidentiality of the data is ensured. A commonly used FPE algorithm is FF1. This algorithm is recommended to be used in Kafka.
Kafka / DSM Integration
With Data Security Manager (DSM), Fortanix provides a feature-rich solution to protect (encryption and tokenization) data in Kafka. It can be installed on-premises as the FX2200 or can be used as a SaaS solution.
In both cases, it offers a web-based and very user-friendly Key Management System (KMS). Such a KMS is required to manage the encryption or tokenization keys, as these are used to protect the data.
But how can Kafka be modified so that it applies protection of data? When looking up the Kafka documentation, the obvious solution would be to use Single Message Transforms. But this is actually not recommended by Confluent when invoking external APIs, which is the case when requesting the tokenization from an external KMS. So, what is the best approach then?
The best option is to use Kafka streams. This is Kafka’s way to modify data within Kafka itself by reading data from one topic and writing it back to a separate topic. At this point, data can be modified and tokenized.
Kafka provides a Scala and Java interface to modify this data. DSM offers a JCE Provider and a mighty REST interface, which can be used for integration. The actual implementation is rather quick. You need a Java class that reaches out to DSM and tokenize the data.
And you need another class that uses the Kafka StreamsBuilder to modify the data. The following simple Java code line will read the data from the topic “input-topic”, will send it to DSM for tokenization and will write it out to the topic “output-topic”:
builder.stream("input-topic").mapValues(value -> dsm.tokenize(value)).to("output-topic")
Here the object builder is an instantiation of StreamsBuilder. The object dsm is the implementation that handles the communication with DSM either through REST or JCE.
The architecture diagram for tokenizing data in Kafka with DSM, using Kafka stream is shown in Figure 2.
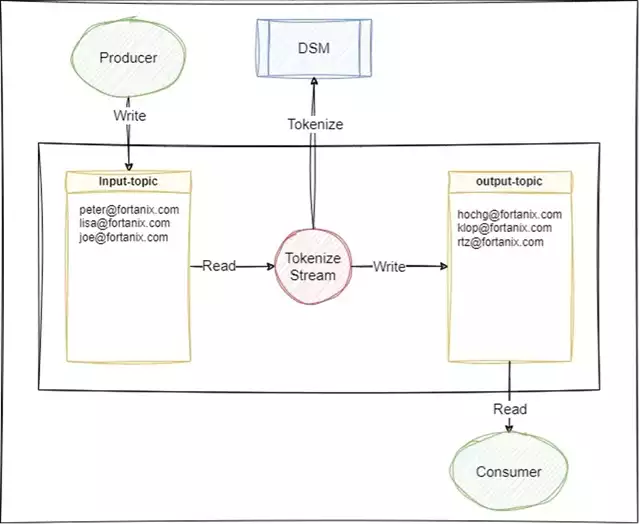
Figure 2: Kafka Stream Tokenization
Please note that two components are added to this diagram. These are a Kafka Producer, which writes data into a topic and a Kafka Consumer that reads data from a topic. The Producer and the Consumer could be Connectors, as described at the beginning of this blog.
In this diagram, the content of the input-topic contains plain email addresses. The content of the output-topic shows tokenized email addresses. Please note that the applied tokenization scheme in this case only tokenizes the username (left part of @ sign) and not the domain (right part of @ sign). Typically, this can be configured as desired.
The tokenization itself is performed by the component DSM in this diagram. It holds the tokenization key and the tokenization scheme required for this operation. After writing the tokenized data into the target topic, the plain data from the source topic should be deleted.
Typical Deployments With 3rd Party Applications
As mentioned at the beginning of this blog, Kafka is only a streaming platform. It receives data from producers and consumers pick it up. We have covered how data can be protected within Kafka.
But typically, data also needs to be protected in transit to 3rd party applications as well. Some cross-product support needs to be available. Very often, you will see data being tokenized within Kafka and then being forwarded to a 3rd party application.
To present the unprotected data to the end user, the data needs to be detokenized by the 3rd party application. This can only be achieved if the 3rd party application gains access to the same tokenization key as well. With DSMs mighty App concept, this can be achieved easily with even different authentication and authorization options.
For example, Kafka could connect to DSM using API key authentication and will only be allowed to tokenize data, while a 3rd party application will authenticate using certificated-based authentication and only being allowed to execute the detokenize operation. This described scenario is commonly used for a deployment together with Snowflake, as depicted in Figure 3.
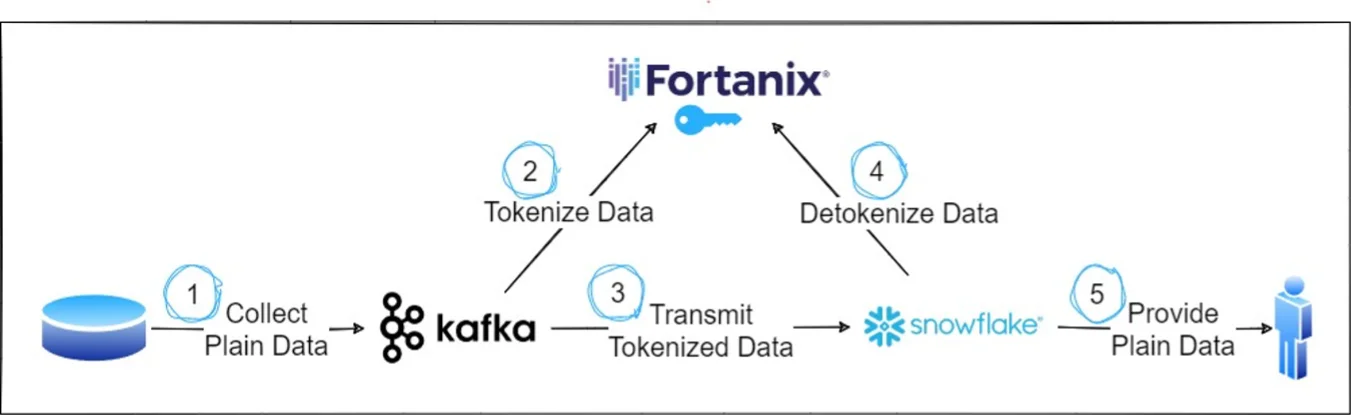
Figure 3: Kafka-Snowflake-DSM Deployment
In this deployment, data is retrieved from any producer and written to Kafka (1). This data is sent to Fortanix DSM, which holds the tokenization key, for tokenization (2) and then the data is stored within Kafka, until it is picked up tokenized by Snowflake (3). In Snowflake, this information is stored permanently in the tokenized fashion. Only, when the end user requests the data, the data is sent to Fortanix DSM for detokenization (4) and then forwarded to the end user in plan (5).
A setup like the one described above ensures that data is never exposed on its way from storing in Kafka till storage in Snowflake and therefore also fulfills compliance requirements for Personally Identifiable Information (PII).
DSM Key Management Capabilities
As we have learned, protecting data requires keys. These need to be managed properly to protect them from misuse and loss. Therefore, the following features of a KMS as found in DSM are essential:
- Easy to use and clear user interface to facilitate the usage and to prevent accidental errors.
- Support of Role Based Access Control (RBAC) to follow the principle of need to know.
- Possibility to create custom roles to conform with principle of least privilege.
- Strong user authentication to prevent account hacking.
- Quorum approval policies to fulfill Zero Trust requirements.
- Tamper protected audit logs as required by compliance regulations.
- Tamper evident key store, ideally a FIPS 140-2 Level 3 compliant HSM.
- Possibility for automation of the system, especially for big companies to reduce time-consuming and error-prone manual interaction.
Conclusion
Kafka is the go-to platform when it comes to streaming scenarios. But it lacks the important feature to protect the sensitive data from leakage or misuse. This missing protection can be applied by integrating with Fortanix DSM.
Hereby, DSM tokenizes all information so that they are always kept secret. DSM shines with its integration flexibility, making it possible to support different authentication schemes and can also be combined with other 3rd party applications.
For more information, please contact Fortanix.





