The On-Premises AI Dilemma


How Enterprises Can Deploy Model Builders' Proprietary AI Model On-Premises and Both Win Without Trusting Each Other
1. The Paralyzing Deadlock of Enterprise AI
Sooner or later, every enterprise LLM deployment and AI initiative hits the same paralyzing wall. It is not a compute problem, and it is not a talent problem. It is a fundamental deadlock of trust and data privacy.
The enterprise says: "We cannot send our regulated data outside our environment to a cloud API."
The AI builder says: "We cannot hand over our proprietary model weights to your data center; it is our core intellectual property."
Historically, this meant stagnation. Either enterprise compromised on data sovereignty, or the AI vendor risked having years of research extracted or replicated. As Jensen Huang highlighted recently at CES, the vision of running proprietary models on-premises for sovereignty, IP protection, and deterministic low-latency inference, is the inevitable next step for the enterprise. We must bring the model to the data.
Beyond compliance and IP protection, there is a third driver that is rapidly moving from "nice to have" to "non-negotiable": inference latency. For enterprises running real-time fraud detection, clinical decision support, algorithmic trading, or customer-facing AI at scale, the round-trip to a cloud API endpoint introduces latency that is simply incompatible with the use case. When the model lives next to the data, you stop paying the latency tax of the public internet.
2. The End of "Naked Compute"
Doing this safely requires a radical architectural shift. The era of "naked compute" is dead.
Traditional perimeter security stops being enough the moment model weights and sensitive data are loaded for secure AI inference. A privileged operator, a compromised hypervisor, or a memory dump can extract sensitive assets in plaintext.
We cannot settle for "zero data retention" as a mere marketing promise. True enterprise deployment, especially in regulated industries, cannot come at the compromise of model integrity or data safety. We need cryptographic proof, not operational promises.
3. The Mechanism: Attestation-Gated Trust
Before describing how this architecture works, it is worth being honest about something the industry rarely says plainly: neither party fully trusts the other, and they are both right not to. The enterprise has no way to verify that a model provider's runtime does not contain telemetry, logging, or exfiltration logic that quietly sends prompts or context back to the vendor's infrastructure. The model builder has no way to verify that a privileged enterprise administrator will not extract weights from memory once the model is running inside their data center. These are not hypothetical concerns or negotiating postures — they are real, rational threat models on both sides of the table. Any architecture that only solves one side of this distrust is not actually solving the problem. It is just shifting who bears the risk.
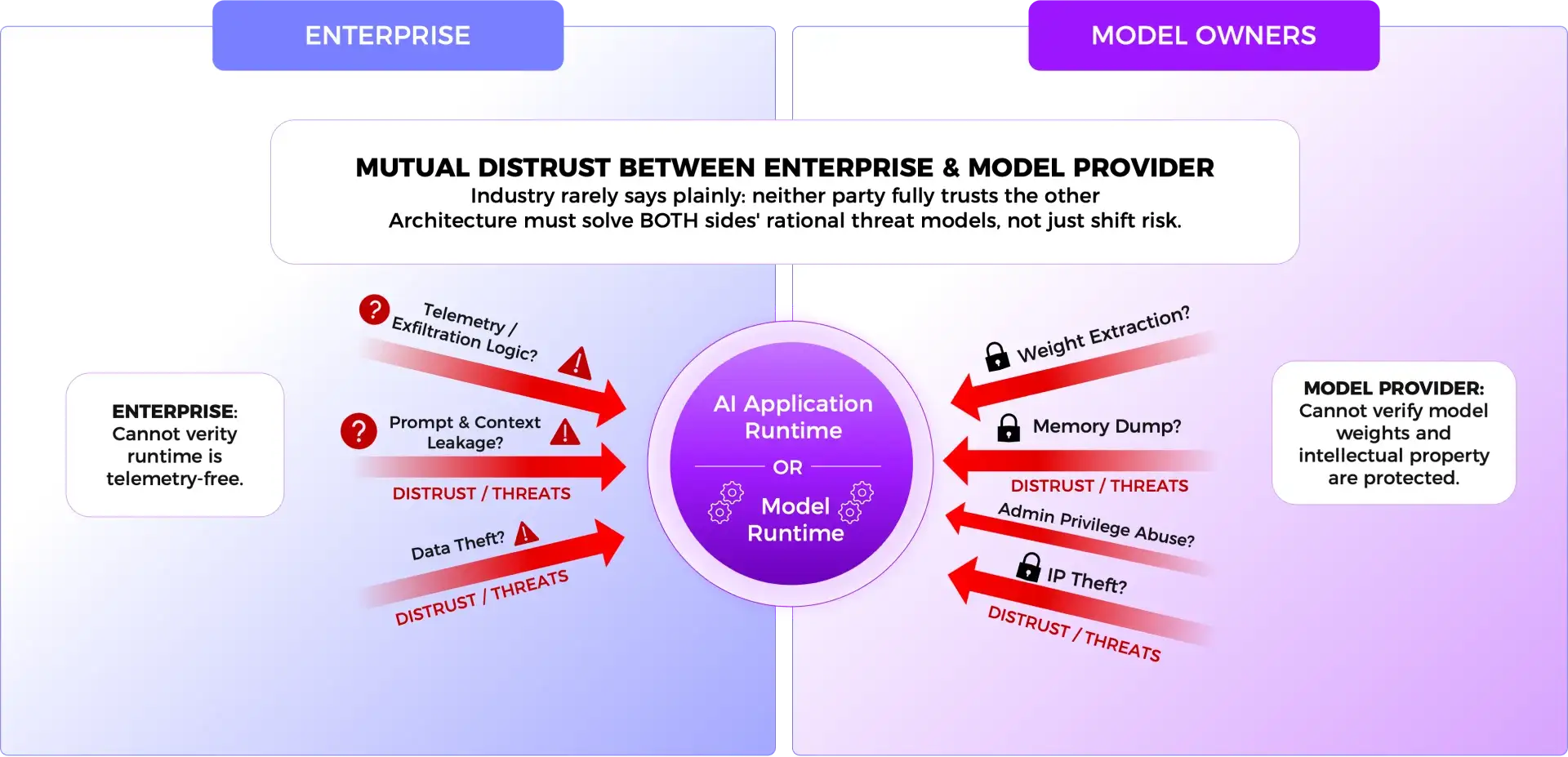
This is precisely why attestation-gated trust matters and why it must work symmetrically. The goal is not to give the model provider a way to protect themselves from the enterprise, or to give the enterprise a way to audit the model provider. The goal is to make both sets of concerns irrelevant through cryptographic enforcement, so neither party must take the other's word for anything.
The model provider does not simply ship weights into an enterprise environment and hope for the best. Model access must be gated by hardware-backed attestation of the approved runtime and infrastructure state.
Only after that verification succeeds are decryption keys released to the approved runtime, allowing inference to proceed inside a hardware-enforced boundary. No security architecture removes all risk, but this paradigm materially reduces the trust surface by verifying runtime integrity before sensitive assets are ever exposed.
The same attestation boundary that prevents the enterprise from extracting model weights also prevents the model provider's runtime from accessing or exfiltrating enterprise data, the proof runs in both directions.
4. The Secure AI Factory: Verifiable Control
The most dangerous moment in any AI deployment is not data in transit or data at rest, it is data and models in use. This is where traditional security architectures go silent, and where the real exposure lives.
Addressing this requires enforcing Zero Trust principles not just at the network perimeter, but also at the workload execution layer itself. By leveraging Fortanix Confidential AI and NVIDIA Confidential Computing, proprietary models run inside a hardware-attested confidential computing environment, meaning that prompts, retrieval context, and inference processing never exist in plaintext outside a verified, hardware-enforced boundary. The infrastructure around the workload, including the hypervisor, the host OS, and even privileged operators cannot observe or extract what is happening inside it.
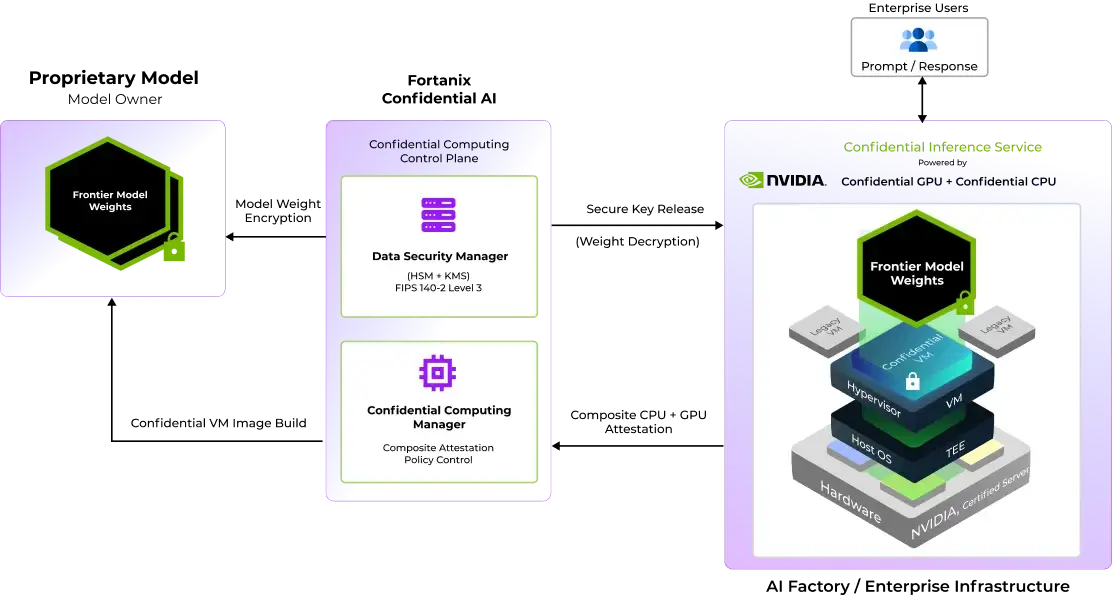
How the Trust Sequence Works
Step 1: Model Weight Encryption Before a single weight ever leaves the model provider's control, it is encrypted. The model is never shipped in plaintext, what arrives in the enterprise environment is mathematically useless without the decryption keys that remain exclusively in the model provider's custody, anchored inside Fortanix Data Security Manager, a FIPS 140-2 Level 3 validated boundary the enterprise operator cannot access or influence.
Step 2: Attestation of Hardware and Software Before those keys move anywhere, Fortanix Confidential Computing Manager demands proof on two fronts simultaneously. The hardware must verify the GPU and CPU composite attestation must confirm that the underlying infrastructure is genuine, unmodified confidential computing silicon, validated against the silicon vendor's own attestation chain NVIDIA, Intel, AMD remote attestation services. And the software image must verify every layer of the runtime environment the container, the inference stack, the full software configuration must match exactly what the model provider has pre-authorized. Both conditions must be true at the same time.
Step 3: Secure Key Release Only after both hardware and software attestation succeed does Fortanix Data Security Manager release the decryption keys automatically, with no human in the loop and no operator override possible. The keys travel to an environment that has proven, cryptographically. The model weights decrypt inside the attested boundary and inference begins. The enterprise never sees the weights in plaintext. They never have custody of the keys.
Step 4: Attestation Failure If either condition in Step 2 fails i.e. if the hardware has been tampered with, if the software image deviates even slightly from the approved configuration, if anything in the trust chain cannot be verified, the keys are never released. The model weights remain encrypted and inaccessible. The deployment environment exists, but the model does not run. There is no fallback, no manual override, no exception process. This is not a limitation of architecture. It is the point of it.
For the enterprise, the result is something that has historically been impossible to guarantee - verifiable sovereignty. Not a contractual promise that your data stayed within your walls, but a cryptographic proof that inference ran exactly where and how it was supposed to.
5. Why This Matters: Unlocking Both Sides of the Deadlock
This architecture does not just secure the workload; it aligns the commercial incentives of both parties.
- For the Enterprise: You achieve data sovereignty and strict AI compliance. You can deploy proprietary models against highly regulated data inside your own environment, without sending prompts or context to an external cloud API.
- For the Model Builder: You achieve enforceable protection of your IP. You gain stronger control over how your weights are accessed and where they are deployed, opening regulated markets that were previously difficult to serve.
This is not theoretical. A leading voice AI model company whose proprietary speech synthesis models represent years of research and significant IP is now deploying within enterprise environments through exactly this architecture. Their enterprise customers, operating under strict data residency requirements, can run inference entirely within their own environment, with cryptographic guarantees that neither prompts nor model weights are ever exposed outside the attested boundary. The model builder protects their IP. The enterprise protects their data. The deadlock is broken.
6. The Era of Naked Compute is Over. Let's Build.
Whether you are an enterprise sitting on highly regulated data that needs unlocking, or an AI model builder looking to deploy proprietary IP behind enterprise firewalls without surrendering control of it, the architecture to break the deadlock exists today. You no longer must choose between data sovereignty and access to proprietary models. You no longer must choose between protecting your IP and reaching regulated markets. The infrastructure is here. The cryptographic guarantees are real.
If you are ready to see it in action:
[Schedule a Confidential AI Architecture Review] A 30-minute working session with our engineering team, tailored to your regulatory environment, your threat model, and your specific deployment constraints. Not a product pitch — a technical conversation.
If you want the full technical picture first:
[Download the Confidential AI Technical Whitepaper] A deep dive into the attestation architecture, hardware trust chain, compliance framework mappings (HIPAA, FedRAMP, SOC 2), and threat model analysis for both enterprise and model provider deployment scenarios.





